
Machine Learning - Logistic Regression
Logistic Regression
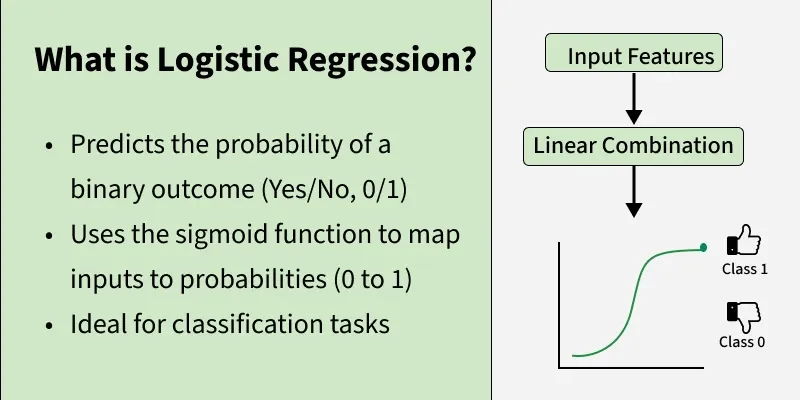
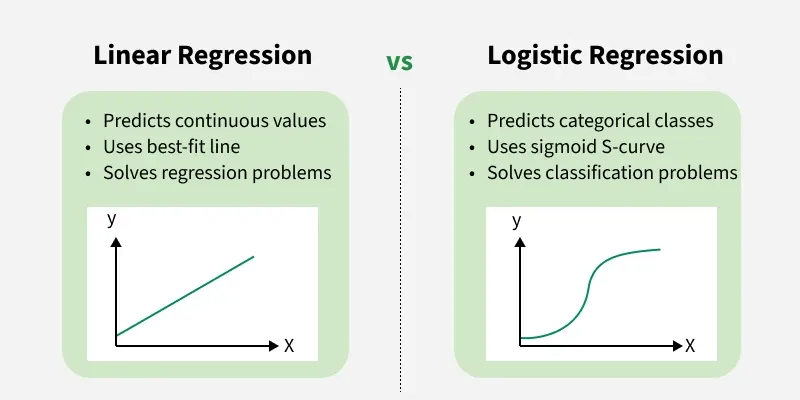
Logistic Regression is a supervised machine learning algorithm used for classification problems. Unlike linear regression which predicts continuous values it predicts the probability that an input belongs to a specific class. Logistic regression aims to solve classification problems. It does this by predicting categorical outcomes, unlike linear regression that predicts a continuous outcome.
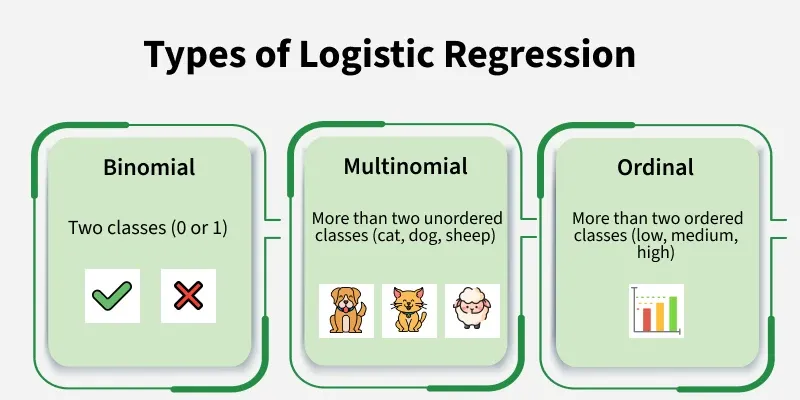
In the simplest case there are two outcomes, which is called binomial, an example of which is predicting if a tumor is malignant or benign. Other cases have more than two outcomes to classify, in this case it is called multinomial. A common example for multinomial logistic regression would be predicting the class of an iris flower between 3 different species.
Here we will be using basic logistic regression to predict a binomial variable. This means it has only two possible outcomes.
How does it work?
In Python we have modules that will do the work for us. Start by importing the NumPy module.
import numpyStore the independent variables in X.
Store the dependent variable in y.
Below is a sample dataset:
Example
#X represents the size of a tumor in centimeters.
X = numpy.array([3.78, 2.44, 2.09, 0.14, 1.72, 1.65, 4.92, 4.37, 4.96, 4.52, 3.69, 5.88]).reshape(-1,1)
#Note: X has to be reshaped into a column from a row for the LogisticRegression() function to work.
#y represents whether or not the tumor is cancerous (0 for "No", 1 for "Yes").
y = numpy.array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1])We will use a method from the sklearn module, so we will have to import that module as well:
from sklearn import linear_modelFrom the sklearn module we will use the LogisticRegression() method to create a logistic regression object.
This object has a method called fit() that takes the independent and dependent values as parameters and fills the regression object with data that describes the relationship:
logr = linear_model.LogisticRegression()
logr.fit(X,y)Now we have a logistic regression object that is ready to predict whether a tumor is cancerous based on the tumor size:
#predict if tumor is cancerous where the size is 3.46mm:
predicted = logr.predict(numpy.array([3.46]).reshape(-1,1))Result
Coefficient
In logistic regression the coefficient is the expected change in log-odds of having the outcome per unit change in X.
This does not have the most intuitive understanding so let's use it to create something that makes more sense, odds.
Example
import numpy
from sklearn import linear_model
#Reshaped for Logistic function.
X = numpy.array([3.78, 2.44, 2.09, 0.14, 1.72, 1.65, 4.92, 4.37, 4.96, 4.52, 3.69, 5.88]).reshape(-1,1)
y = numpy.array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
logr = linear_model.LogisticRegression()
logr.fit(X,y)
log_odds = logr.coef_
odds = numpy.exp(log_odds)
print(odds)Result
This tells us that as the size of a tumor increases by 1mm the odds of it being a cancerous tumor increases by 4x.
Probability
The coefficient and intercept values can be used to find the probability that each tumor is cancerous.
Example
def logit2prob(logr, x):
log_odds = logr.coef_ * x + logr.intercept_
odds = numpy.exp(log_odds)
probability = odds / (1 + odds)
return(probability)Function Explained
To find the log-odds for each observation, we must first create a formula that looks similar to the one from linear regression, extracting the coefficient and the intercept.
log_odds = logr.coef_ * x + logr.intercept_To then convert the log-odds to odds we must exponentiate the log-odds.
odds = numpy.exp(log_odds)Now that we have the odds, we can convert it to probability by dividing it by 1 plus the odds.
probability = odds / (1 + odds)Let us now use the function with what we have learned to find out the probability that each tumor is cancerous.
Example
import numpy
from sklearn import linear_model
X = numpy.array([3.78, 2.44, 2.09, 0.14, 1.72, 1.65, 4.92, 4.37, 4.96, 4.52, 3.69, 5.88]).reshape(-1,1)
y = numpy.array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
logr = linear_model.LogisticRegression()
logr.fit(X,y)
def logit2prob(logr, X):
log_odds = logr.coef_ * X + logr.intercept_
odds = numpy.exp(log_odds)
probability = odds / (1 + odds)
return(probability)
print(logit2prob(logr, X))Result:
- [[0.60749955]
- [0.19268876]
- [0.12775886]
- [0.00955221]
- [0.08038616]
- [0.07345637]
- [0.88362743]
- [0.77901378]
- [0.88924409]
- [0.81293497]
- [0.57719129]
- [0.96664243]]
Results Explained
3.78 0.61 The probability that a tumor with the size 3.78cm is cancerous is 61%.
2.44 0.19 The probability that a tumor with the size 2.44cm is cancerous is 19%.
2.09 0.13 The probability that a tumor with the size 2.09cm is cancerous is 13%.